Sim CSE
SimCSE是NLP的一种对比学习方案,对比学习的标准流程是同一个样本通过不同的数据扩增手段得到的结果视为正样本对,而batch内的所有其他样本视为负样本,然后就是通过loss来缩小正样本的距离、拉大负样本的距离了。
所以难度主要集中在数据扩增手段上。对于NLP来说,我们很难人工构建保证语义不变的数据扩增,所以SimCSE干脆不人工进行数据扩增,而是通过“Dropout两次”的方式来得到同一个输入的不同特征向量,并将它们视为正样本对。奇怪的是,这个简单的“Dropout两次”构造正样本,看上去是一种“无可奈何”的妥协选择,但消融实验却发现它几乎优于所有其他数据扩增方法,令人惊讶之余又让人感叹“大道至简”。
在实现上,SimCSE也相当简单,所谓“Dropout两次”,只需要将样本重复地输入到模型,然后计算相应的loss就行了。由于Dropout本身的随机性,每个样本的Dropout模式都是不一样的,所以只要单纯地重复样本,就可以实现“Dropout两次”的效果。
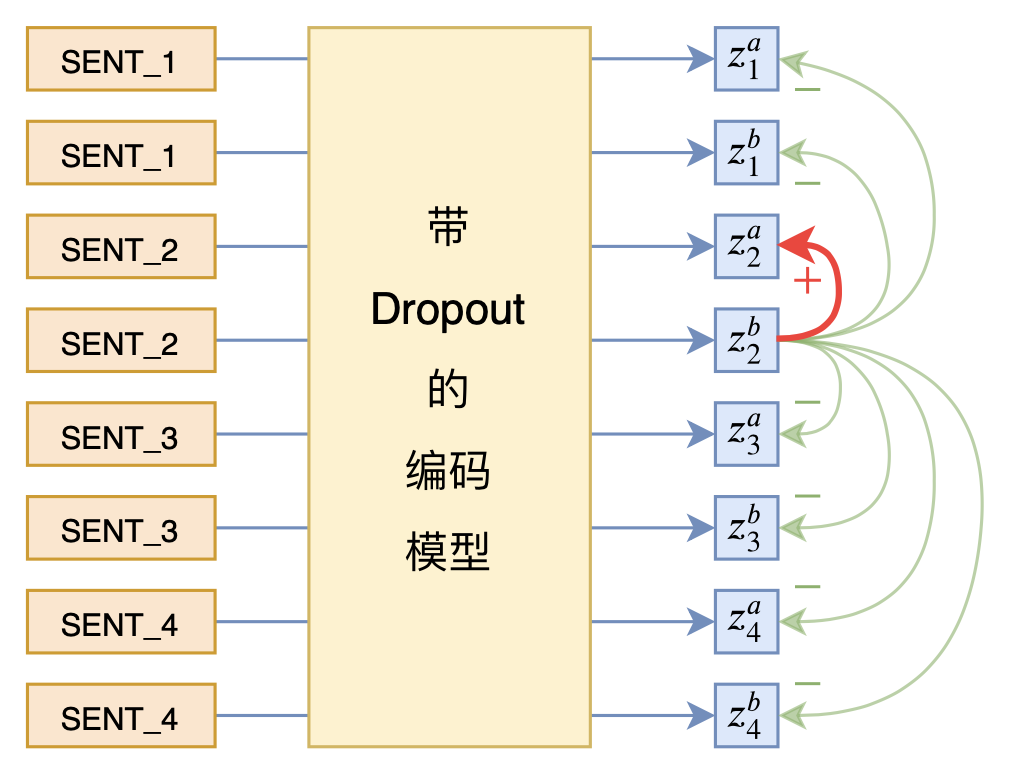
从结果上来看,SimCSE就是希望Dropout对模型结果不会有太大影响,也就是模型输出对Dropout是鲁棒的。
无监督
同一个输入句子,dropout不同的输出作为一对正样例
用dropout来做数据增强,比其他数据增强方法好
有监督
整体好于无监督
矛盾(一个标签)作为负例可以进一步提升效果
参考资料
Last updated