BERT
BERT 全称为 Bidirectional Encoder Representations from Transformer,是谷歌在 2018 年 10 月发布的语言表示模型。BERT 通过维基百科和书籍语料组成的庞大语料进行了预训练,使用时只要根据下游任务进行输出层的修改和模型微调训练,就可以得到很好的效果。BERT 发布之初,就在 GLUE、MultiNLI、SQuAD 等评价基准和数据集上取得了超越当时最好成绩的结果。
BERT结构详解
根据参数设置的不同,Google 论文中提出了Base和Large两种BERT模型。

BERT 的整体结构如下图所示,其是以 Transformer 为基础构建的,使用 WordPiece 的方法进行数据预处理,最后通过 MLM 任务和下个句子预测任务进行预训练的语言表示模型。下面我们从 BERT 的结构:Transformer 出发,来一步步详细解析一下 BERT。

来自:https://doc.shiyanlou.com/courses/uid522453-20190919-1568876896467
BERT 包含 12 个 Transformer 层,每层接受一组 token 的 embeddings 列表作为输入,并产生相同数目的 embeddings 作为输出(当然,它们的值是不同的)。
需要注意的是,与Transformer本身的Encoder端相比,BERT的Transformer Encoder端输入的向量表示,多了Segment Embeddings。
Transformer部分参考:
输入表示
针对不同的任务,BERT模型的输入可以是单句或者句对。对于每一个输入的Token,它的表征由其对应的词表征(Token Embedding)、段表征(Segment Embedding)和位置表征(Position Embedding)相加产生,如图所示:
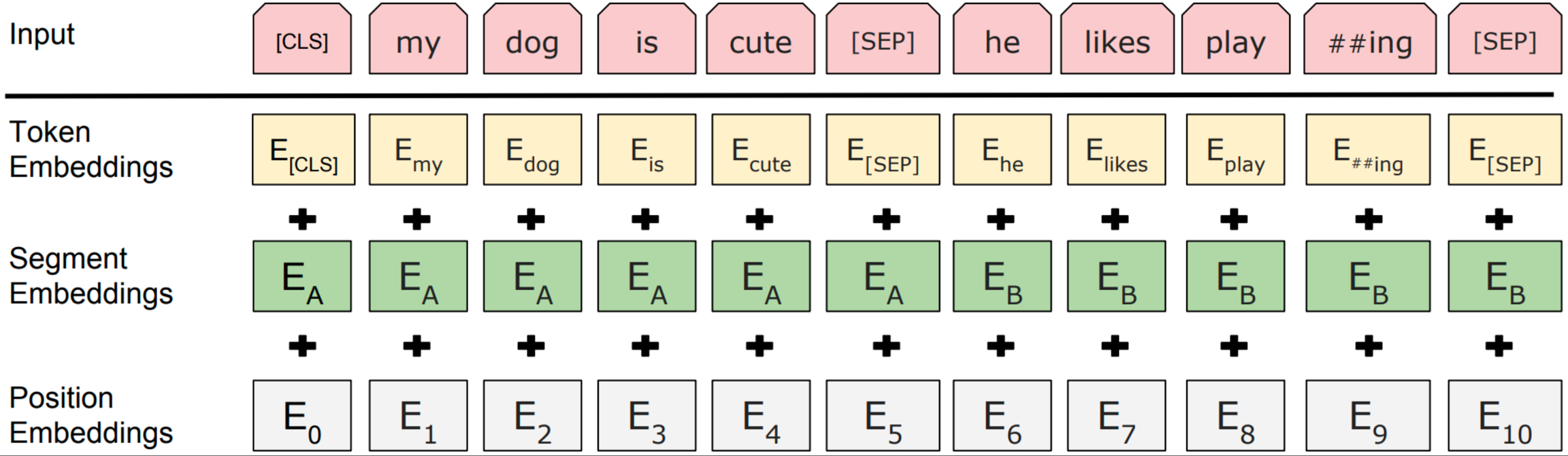
BERT模型的输入表示
对于英文模型,使用了Wordpiece模型来产生Subword从而减小词表规模;对于中文模型,直接训练基于字的模型。
模型输入需要附加一个起始Token,记为[CLS],对应最终的Hidden State(即Transformer的输出)可以用来表征整个句子,用于下游的分类任务。
模型能够处理句间关系。为区别两个句子,用一个特殊标记符[SEP]进行分隔,另外针对不同的句子,将学习到的Segment Embeddings 加到每个Token的Embedding上。
对于单句输入,只有一种Segment Embedding;对于句对输入,会有两种Segment Embedding。
主要输入是文本中各个字/词(或者称为token)的原始词向量,该向量既可以随机初始化,也可以利用Word2Vector等算法进行预训练以作为初始值
Segment Embeddings:该向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字/词的语义信息相融合
Position Embeddings:对不同位置的字/词分别附加一个不同的向量以作区分
token embedding、segment embedding、position embedding都是随机生成的,模型训练。
BERT的输入mask,有文本的位置是1,其他位置是0(pad,CLS等)
在传统的NLP机器学习问题中,我们倾向于清除不需要的文本,例如删除停用词,标点符号,删除符号和数字等。但是,在BERT中,不需要执行此类预处理任务,因为BERT使用了这些 单词的顺序和位置,以了解用户输入的意图。
分词方法 WordPiece
BERT 在对数据预处理时,使用了 WordPiece 的方法,WordPiece 从字面意思理解就是把字词拆成一片一片的。
举个例子来讲,如 look,looked,looking 这三个词,它们其实有同样的意思,但如果我们以词作为单位,那它们就会被认为成不同的词。在英语中这样的情况十分常见,所以为了解决这个问题,WordPiece 会把这三个词拆分成 look,look 和 ##ed,look 和 ##ing,这个方法把词本身和时态表示拆分开,不但能够有效减少词表的大小,提高效率,还能够提升词的区分度。
不过,这个方法对中文是无效的,因为在中文中每个字都是最小的单位,不像英文使用空格分词,并且许多词还能够进一步拆分,所以对中文使用 WordPiece 就相当于按字分割,这也是 BERT 的中文预训练模型的一个局限。因此,尽管 BERT 中文预训练模型效果很好,但也还存在可以改进的空间。有一些研究者就从这个角度出发对中文 BERT 进行了改进,如这篇论文:中文全词覆盖 BERT ,研究者在预训练的数据处理过程中将原 BERT 中 WordPiece 的分词方法换成了中文分词的方法,然后对词整体添加掩膜,最后进行预训练。在中文数据集测试上,使用这个改进后的预训练模型的测试结果优于使用原版 BERT 的中文预训练模型的测试结果。
输出
输出是文本中各个字/词融合了全文语义信息后的向量表示。
BERT 具有两种输出,一个是pooler output,对应的 [CLS]的输出,以及sequence output,对应的是序列中的所有字的最后一层hidden输出。 所以BERT主要可以处理两种,一种任务是分类/回归任务(使用的是pooler output),一种是序列任务(sequence output)。
官方bert一般返回四个值,一个是最后一层输出,一个是预测值,一个是隐藏层,一个是attention。
last_hidden_state:shape是(batch_size, sequence_length, hidden_size),hidden_size=768,它是模型最后一层输出的隐藏状态。(通常用于命名实体识别) pooler_output:shape是(batch_size, hidden_size),这是序列的第一个token(classification token)的最后一层的隐藏状态,它是由线性层和Tanh激活函数进一步处理的。这个输出不是对输入的语义内容的一个很好的总结,对于整个输入序列的隐藏状态序列的平均化或池化通常更好。(通常用于句子分类,至于是使用这个表示,还是使用整个输入序列的隐藏状态序列的平均化或池化,视情况而定) hidden_states:这是输出的一个可选项,如果输出,需要指定config.output_hidden_states=True,它也是一个元组,它的第一个元素是embedding,其余元素是各层的输出,每个元素的形状是(batch_size, sequence_length, hidden_size) attentions:这也是输出的一个可选项,如果输出,需要指定config.output_attentions=True,它也是一个元组,它的元素是每一层的注意力权重,用于计算self-attention heads的加权平均值。
一般来说,后面+CNN、RNN等结构的时候就取last_hidden_state,如果只是加个线性层做分类就取pooler_output。
有篇文章做了个实验,fine-tuning的时候,用pooler output更好,没有fine-tuning的时候用last hidden state更好。文章是Tips and Tricks for your BERT based applications
BERT 预训练模型
BERT 在预训练阶段的两个任务:遮蔽语言模型(Masked Language Model(MLM))和句子预测任务(Next Sentence Prediction(NSP))。这两个任务使得 BERT 学到了对自然语言的理解。
遮蔽语言模型
与常见的训练从左向右语言模型(Left-To-Right Language Model)的预训练任务不同,BERT 是以训练遮蔽语言模型(Masked Language Model)作为预训练目标,具体来说就是把输入的语句中的字词随机用 [Mask] 标签覆盖,然后训练模型结合被覆盖的词的左侧和右侧上下文进行预测。可以看出,BERT 的做法与从左向右语言模型只通过左侧语句预测下一个词的做法相比,遮蔽语言模型能够生成同时融合了左、右上下文的语言表示。这种做法能够使 BERT 学到字词更完整的语义表示 。思想来源于完形填空的任务。
BERT模型为什么要用mask?
BERT通过在输入X中随机Mask掉一部分单词,然后预训练过程的主要任务之一是根据上下文单词来预测这些被Mask掉的单词。其实这个就是典型的Denosing Autoencoder的思路,那些被Mask掉的单词就是**在输入侧加入的所谓噪音。**类似BERT这种预训练模式,被称为DAE LM。因此总结来说BERT模型 [Mask] 标记就是引入噪音的手段。
关于DAE LM预训练模式,优点是它能比较自然地融入双向语言模型,同时看到被预测单词的上文和下文,然而缺点也很明显,主要在输入侧引入[Mask]标记,导致预训练阶段和Fine-tuning阶段不一致的问题。
这样做会产生两个缺点:
(1)会造成预训练和微调时的不一致,因为在微调时[MASK]总是不可见的;
(2)由于每个Batch中只有15%的词会被预测,因此模型的收敛速度比起单向的语言模型会慢,训练花费的时间会更长。
对于第一个缺点的解决办法是,**把80%需要被替换成[MASK]的词进行替换,10%的随机替换为其他词,10%保留原词。由于Transformer Encoder并不知道哪个词需要被预测,哪个词是被随机替换的,这样就强迫每个词的表达需要参照上下文信息。**对于第二个缺点目前没有有效的解决办法,但是从提升收益的角度来看,付出的代价是值得的。
BERT并不知道[MASK]替换的是这15%个Token中的哪一个词(注意:这里意思是输入的时候不知道[MASK]替换的是哪一个词,但是输出还是知道要预测哪个词的)
这么做的主要原因是:在后续微调任务中语句中并不会出现 [MASK] 标记,而且这么做的另一个好处是:预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇( 10% 概率),这就迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力。上述提到了这样做的一个缺点,其实这样做还有另外一个缺点,就是每批次数据中只有 15% 的标记被预测,这意味着模型可能需要更多的预训练步骤来收敛。
BERT 的论文中提到,增加掩膜的具体方式为:先对语句进行 WordPiece 分割,分割后选择句中 15% 的字符,例如选择到了第 i 字符,接下来:
以 80% 的概率使用
[Mask]替换。以 10% 的概率使用一个随机的字符替换。
以 10% 的概率不进行操作。
下面我们使用在 PyTorch-Transformers 模型库中封装好的 BERTForMaskedLM() 类来实际看一下 BERT 在预训练后对遮蔽字的预测效果。首先,需要安装 PyTorch-Transformers。
PyTorch-Transformers 是一个以 PyTorch 深度学习框架为基础构建的自然语言处理预训练模型库,早前称之为 pytorch-pretrained-bert,如今已正式成为独立项目。
使用 PyTorch-Transformers 模型库,先设置好准备输入模型的例子,使用 BertTokenizer() 建立分词器对象对原句进行分词,然后对照词表将词转换成序号。
接下来使用 BertForMaskedLM() 建立模型,并将模型设置模型成验证模式。由于 BERT 模型体积很大,且托管在外网,所以本次先从网盘下载链接:https://pan.baidu.com/s/1afwmZEXZUFnmSwm6eEvmyg提取码:qkuc
此时,我们已经准备好了待输入的语句和预训练模型,接下来需要做的就是让模型去预测的覆盖的词的序号。
最后找到预测值中最大值对应的序号,然后通过 tokenizer.convert_ids_to_tokens() 在词表中查找,转换成对应的字。
输出结果应该是:
可以看到,最后的预测结果是正确的的,说明 BERT 真的对语言有了理解。
句子预测任务
为了训练一个理解句子间关系的模型,引入一个下一句预测任务。这一任务的训练语料可以从语料库中抽取句子对包括两个句子A和B来进行生成,其中50%的概率B是A的下一个句子,50%的概率B是语料中的一个随机句子。NSP任务预测B是否是A的下一句。NSP的目的是获取句子间的信息,这点是语言模型无法直接捕捉的。
这个类似于段落重排序的任务,即:将一篇文章的各段打乱,让我们通过重新排序把原文还原出来,这其实需要我们对全文大意有充分、准确的理解。Next Sentence Prediction 任务实际上就是段落重排序的简化版:只考虑两句话,判断是否是一篇文章中的前后句。在实际预训练过程中,文章作者从文本语料库中随机选择 50% 正确语句对和 50% 错误语句对进行训练,与 Masked LM 任务相结合,让模型能够更准确地刻画语句乃至篇章层面的语义信息。
Google的论文结果表明,这个简单的任务对问答和自然语言推理任务十分有益,但是后续一些新的研究[15]发现,去掉NSP任务之后模型效果没有下降甚至还有提升。
下面我们使用 PyTorch-Transformers 库中的句子预测模型进行,观察一下输出结果。
首先构造输入样本,然后进行分词和词向序号的转换。
构造句子的分段 id,按照上下句分别标为 0 和 1。
接下来使用 BertForNextSentencePrediction() 初始化模型,再加载 BERT 的预训练参数。
最后将样本输入模型进行预测,输出模型的预测结果。
最终的输出结果应该是:[0, 1]。
0 表示是上下句关系,1 表示不是上下句关系。因此从上面结果可以看到,模型预测第一个句子对是上下句关系,第二个句子对不是,对于这两个样本 BERT 的预测正确。
我们通过两个例子来看 BERT 的效果,都是非常理想的。实际上,BERT 效果好的原因主要有两点:
使用的双向的 Transformer 结构学习到左、右两侧上下文语境。
使用完整的文档语料训练而不是打乱的句子,配合下个句子预测任务,从而学习到了捕捉很长的连续语句中的信息的能力。
损失函数
BERT的损失函数由两部分组成,第一部分是来自 Mask-LM 的单词级别分类任务,另一部分是句子级别的分类任务。通过这两个任务的联合学习,可以使得 BERT 学习到的表征既有 token 级别信息,同时也包含了句子级别的语义信息。具体损失函数如下:

具体的预训练工程实现细节方面,BERT 还利用了一系列策略,使得模型更易于训练,比如对于学习率的 warm-up 策略,使用的激活函数不再是普通的 ReLu,而是 GeLu,也使用了 dropout 等常见的训练技巧。
BERT Finetune
当使用 BERT 完成文本分类时,通常有 2 种方案:
从预训练好的 BERT 模型中提取特征向量,即 Feature Extraction 方法。
将下游任务模型添加到 BERT 模型之后,然后使用下游任务的训练集对进行训练,即 Fine-Tuning 方法。
通常 Fine-Tuning 方法更常被人们使用,因为通过结合下游任务的数据集进行微调从而调整预训练模型参数,使模型能够更好捕捉到下游任务的数据特征。
Fine-tuning 的优势
在本教程中,我们将使用BERT来训练一个文本分类器。具体来说,我们将采取预训练的 BERT 模型,在末端添加一个未训练过的神经元层,然后训练新的模型来完成我们的分类任务。为什么要这样做,而不是训练一个特定的深度学习模型(CNN、BiLSTM等)?
更快速的开发。首先,预训练的 BERT 模型权重已经编码了很多关于我们语言的信息。因此,训练我们的微调模型所需的时间要少得多——就好像我们已经对网络的底层进行了广泛的训练,只需要将它们作为我们的分类任务的特征,并轻微地调整它们就好。事实上,作者建议在特定的 NLP 任务上对 BERT 进行微调时,只需要 2-4 个 epochs 的训练(相比之下,从头开始训练原始 BERT 或 LSTM 模型需要数百个 GPU 小时)。
更少的数据。此外,也许同样重要的是,预训练这种方法,允许我们在一个比从头开始建立的模型所需要的数据集小得多的数据集上进行微调。从零开始建立的 NLP 模型的一个主要缺点是,我们通常需要一个庞大的数据集来训练我们的网络,以达到合理的精度,这意味着我们必须投入大量的时间和精力在数据集的创建上。通过对 BERT 进行微调,我们现在可以在更少的数据集上训练一个模型,使其达到良好的性能。
更好的结果。最后,这种简单的微调程过程(通常在 BERT 的基础上增加一个全连接层,并训练几个 epochs)被证明可以在广泛的任务中以最小的调节代价来实现最先进的结果:分类、语言推理、语义相似度、问答问题等。与其实现定制的、有时还很难理解的网络结构来完成特定的任务,不如使用 BERT 进行简单的微调,也许是一个更好的(至少不会差)选择。
BERT 要求我们:
在句子的句首和句尾添加特殊的符号
在每个句子的结尾,需要添加特殊的 [SEP] 符号。在以输入为两个句子的任务中(例如:句子 A 中的问题的答案是否可以在句子 B 中找到),该符号为这两个句子的分隔符。
在分类任务中,我们需要将 [CLS] 符号插入到每个句子的开头。这个符号有特殊的意义,BERT 包含 12 个 Transformer 层,每层接受一组 token 的 embeddings 列表作为输入,并产生相同数目的 embeddings 作为输出(当然,它们的值是不同的)。**最后一层 transformer 的输出,只有第 1 个 embedding(对应到 [CLS] 符号)会输入到分类器中。你也许会想到对最后一层的 embeddings 使用一些池化策略,但没有必要。**因为 BERT 就是被训练成只使用 [CLS] 来做分类,它会把分类所需的一切信息编码到 [CLS] 对应的 768 维 embedding 向量中,相当于它已经为我们做好了池化工作。
给句子填充 or 截断,使每个句子保持固定的长度。
所有句子必须被填充或截断到固定的长度,句子最大的长度为 512 个 tokens。
填充句子要使用 [PAD] 符号,它在 BERT 词典中的下标为 0
句子的最大长度配置会影响训练和评估速度。
用 “attention mask” 来显示的区分填充的 tokens 和非填充的 tokens。
“Attention Mask” 是一个只有 0 和 1 组成的数组,标记哪些 tokens 是填充的(0),哪些不是的(1)。掩码会告诉 BERT 中的 “Self-Attention” 机制不去处理这些填充的符号。
在微调过程中,BERT 的作者建议使用以下超参 (from Appendix A.3 of the BERT paper )::
批量大小:16, 32
学习率(Adam):5e-5, 3e-5, 2e-5
epochs 的次数:2, 3, 4
常见任务
双句分类任务。两句拼起来,加上[CLS]和[SEP],直接取[CLS]位置输出向量预测,进行 finetune。
单句分类任务。直接拿单句,前面加入[CLS]输入,之后同样取[CLS]位置输出来预测,进行 finetune。
问答(QA)任务。将问题和答题所需上下文分别作为上句与下句,加入[CLS]和[SEP]特殊符,之后通过在上下文部分预测答案所在位置开头(Start)与结尾(End),进行 finetune。
单句标注任务。类似单句分类,先加入[CLS],但是最后取其他位置输出,预测相应标注,进行 finetune。
针对句子语义相似度的任务
实际操作时,[CLS]+句子1+[SEP]+句子2+[SEP],语义相似度任务将两个句子按照上述方式输入即可,之后与论文中的分类任务一样,将[CLS] token位置对应的输出,接上softmax做分类即可(实际上GLUE任务中就有很多语义相似度的数据集)。
针对多标签分类的任务
对于多标签分类任务,显而易见的朴素做法就是不管样本属于几个类,就给它训练几个分类模型即可,然后再一一判断在该类别中,其属于那个子类别,但是这样做未免太暴力了,而多标签分类任务,其实是可以只用一个模型来解决的。
利用BERT模型解决多标签分类问题时,其输入与普通单标签分类问题一致,得到其embedding表示之后(也就是BERT输出层的embedding),有几个label就连接到几个全连接层(也可以称为projection layer),然后再分别接上softmax分类层,这样的话会得到loss1, loss2, ...。最后再将所有的loss相加起来即可。这种做法就相当于将n个分类模型的特征提取层参数共享,得到一个共享的表示(其维度可以视任务而定,由于是多标签分类任务,因此其维度可以适当增大一些),最后再做多标签分类任务。
针对翻译的任务
针对翻译的任务,我自己想到一种做法,因为BERT本身会产生embedding这样的“副产品”,因此可以直接利用BERT输出层得到的embedding,然后在做机器翻译任务时,将其作为输入/输出的embedding表示,这样做的话,可能会遇到UNK的问题,为了解决UNK的问题,可以将得到的词向量embedding拼接字向量的embedding得到输入/输出的表示(对应到英文就是token embedding拼接经过charcnn的embedding的表示)。
针对文本生成的任务
关于生成任务,搜到以下几篇论文:
BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model
MASS: Masked Sequence to Sequence Pre-training for Language Generation
Unified Language Model Pre-training for Natural Language Understanding and Generation
模型上线
#td
工业实践
知识融入
BERT在自然语言理解任务上取得了巨大的成功,但也存在着一些不足。
**其一是常识(Common Sense)的缺失。**人类日常活动需要大量的常识背景知识支持,BERT学习到的是样本空间的特征、表征,可以看作是大型的文本匹配模型,而大量的背景常识是隐式且模糊的,很难在预训练数据中进行体现。
**其二是缺乏对语义的理解。**模型并未理解数据中蕴含的语义知识,缺乏推理能力。在美团点评搜索场景中,需要首先对用户输入的Query进行意图识别,以确保召回结果的准确性。比如,对于“宫保鸡丁”和“宫保鸡丁酱料”两个Query,二者的BERT语义表征非常接近,但是蕴含的搜索意图却截然不同。前者是菜品意图,即用户想去饭店消费,而后者则是商品意图,即用户想要从超市购买酱料。在这种场景下,BERT模型很难像正常人一样做出正确的推理判断。
为了处理上述情况,美团尝试在MT-BERT预训练过程中融入知识图谱信息。
BERT在进行语义建模时,主要聚焦最原始的单字信息,却很少对实体进行建模。具体地,BERT为了训练深层双向的语言表征,采用了Masked LM(MLM)训练策略。该策略类似于传统的完形填空任务,即在输入端,随机地“遮蔽”掉部分单字,在输出端,让模型预测出这些被“遮蔽”的单字。模型在最初并不知道要预测哪些单字,因此它输出的每个单字的嵌入表示,都涵盖了上下文的语义信息,以便把被“掩盖”的单字准确的预测出来。
BERT模型通过字的搭配(比如“全X德”),很容易推测出被“掩盖”字信息(“德”),但这种做法只学习到了实体内单字之间共现关系,并没有学习到实体的整体语义表示。因此,我们使用Knowledge-aware Masking的方法来预训练MT-BERT。具体的做法是,输入仍然是字,但在随机”遮蔽”时,不再选择遮蔽单字,而是选择“遮蔽”实体对应的词。这需要我们在预训练之前,对语料做分词,并将分词结果和图谱实体对齐。
模型轻量化
为了减少模型响应时间,满足上线要求,业内主要有三种模型轻量化方案。
低精度量化。在模型训练和推理中使用低精度(FP16甚至INT8、二值网络)表示取代原有精度(FP32)表示。
模型裁剪和剪枝。减少模型层数和参数规模。
模型蒸馏。通过知识蒸馏方法[22]基于原始BERT模型蒸馏出符合上线要求的小模型。
图8展示了基于BERT模型微调可以支持的任务类型,包括句对分类、单句分类、问答(机器阅读理解)和序列标注任务。
句对分类任务和单句分类任务是句子级别的任务。预训练中的NSP任务使得BERT中的“[CLS]”位置的输出包含了整个句子对(句子)的信息,我们利用其在有标注的数据上微调模型,给出预测结果。
问答和序列标注任务都属于词级别的任务。预训练中的MLM任务使得每个Token位置的输出都包含了丰富的上下文语境以及Token本身的信息,我们对BERT的每个Token的输出都做一次分类,在有标注的数据上微调模型并给出预测。

单句分类
细粒度情感分析
为了更全面更真实的描述商家各属性情况,细粒度情感分析需要判断评论文本在各个属性上的情感倾向(即正面、负面、中立)。为了优化美团点评业务场景下的细粒度情感分析效果,NLP中心标注了包含6大类20个细粒度要素的高质量数据集,标注过程中采用严格的多人标注机制保证标注质量,并在AI Challenger 2018细粒度情感分析比赛中作为比赛数据集验证了效果,吸引了学术界和工业届大量队伍参赛。
针对细粒度情感分析任务,我们设计了基于MT-BERT的多任务分类模型,模型结构如图9所示。模型架构整体分为两部分:一部分是各情感维度的参数共享层(Share Layers),另一部分为各情感维度的参数独享层(Task-specific Layers)。其中参数共享层采用了MT-BERT预训练语言模型得到文本的上下文表征。MT-BERT依赖其深层网络结构以及海量数据预训练,可以更好的表征上下文信息,尤其擅长提取深层次的语义信息。 参数独享层采用多路并行的Attention+Softmax组合结构,对文本在各个属性上的情感倾向进行分类预测。通过MT-BERT优化后的细粒度情感分析模型在Macro-F1上取得了显著提升。
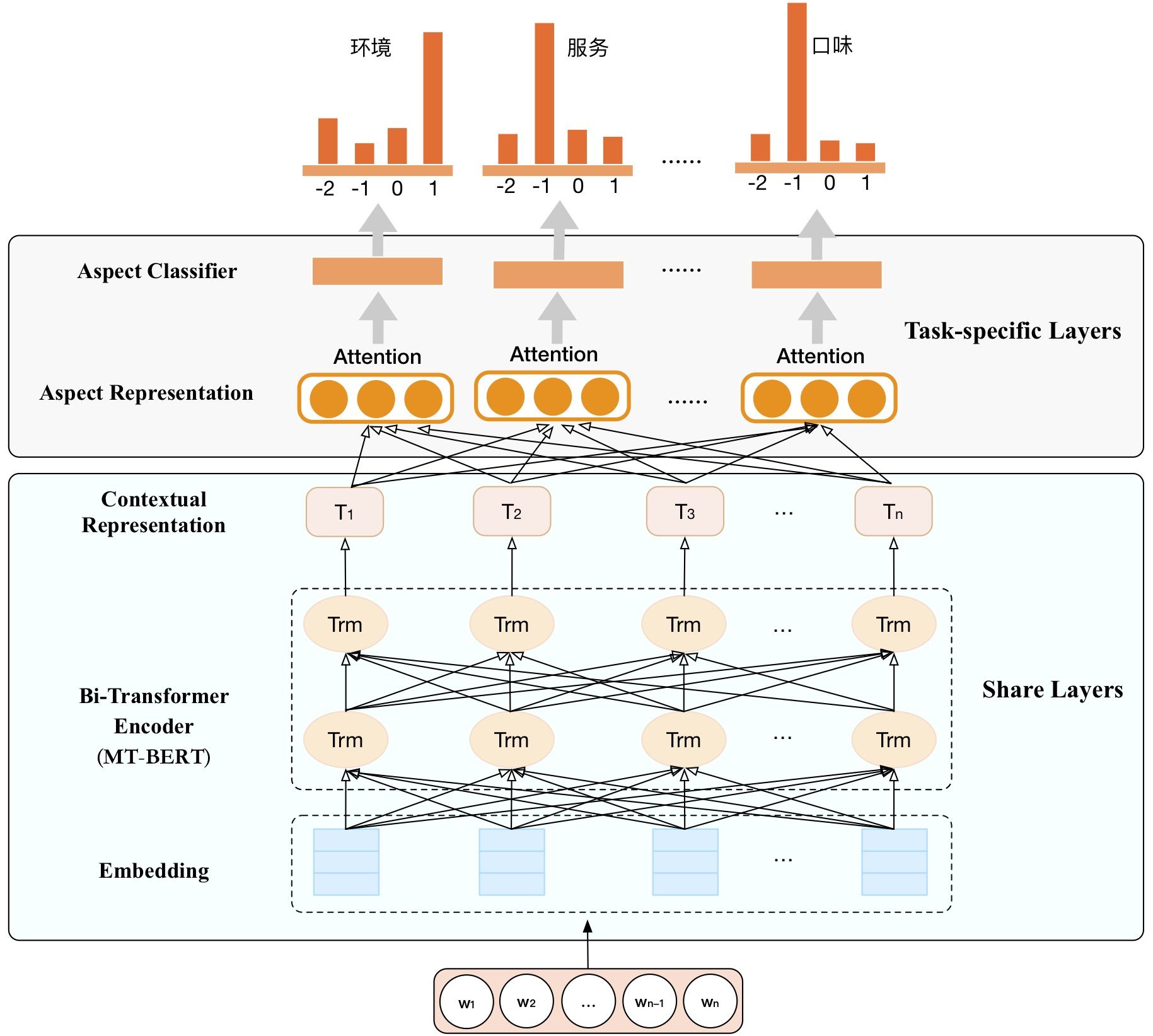
图9 基于MT-BERT的多任务细粒度情感分析模型架构
细粒度情感分析的重要应用场景之一是大众点评的精选点评模块,如图10所示。精选点评模块作为点评App用户查看高质量评论的入口,其中精选点评标签承载着结构化内容聚合的作用,支撑着用户高效查找目标UGC内容的需求。细粒度情感分析能够从不同的维度去挖掘评论的情感倾向。基于细粒度情感分析的情感标签能够较好地帮助用户筛选查看,同时外露更多的POI信息,帮助用户高效的从评论中获取消费指南。
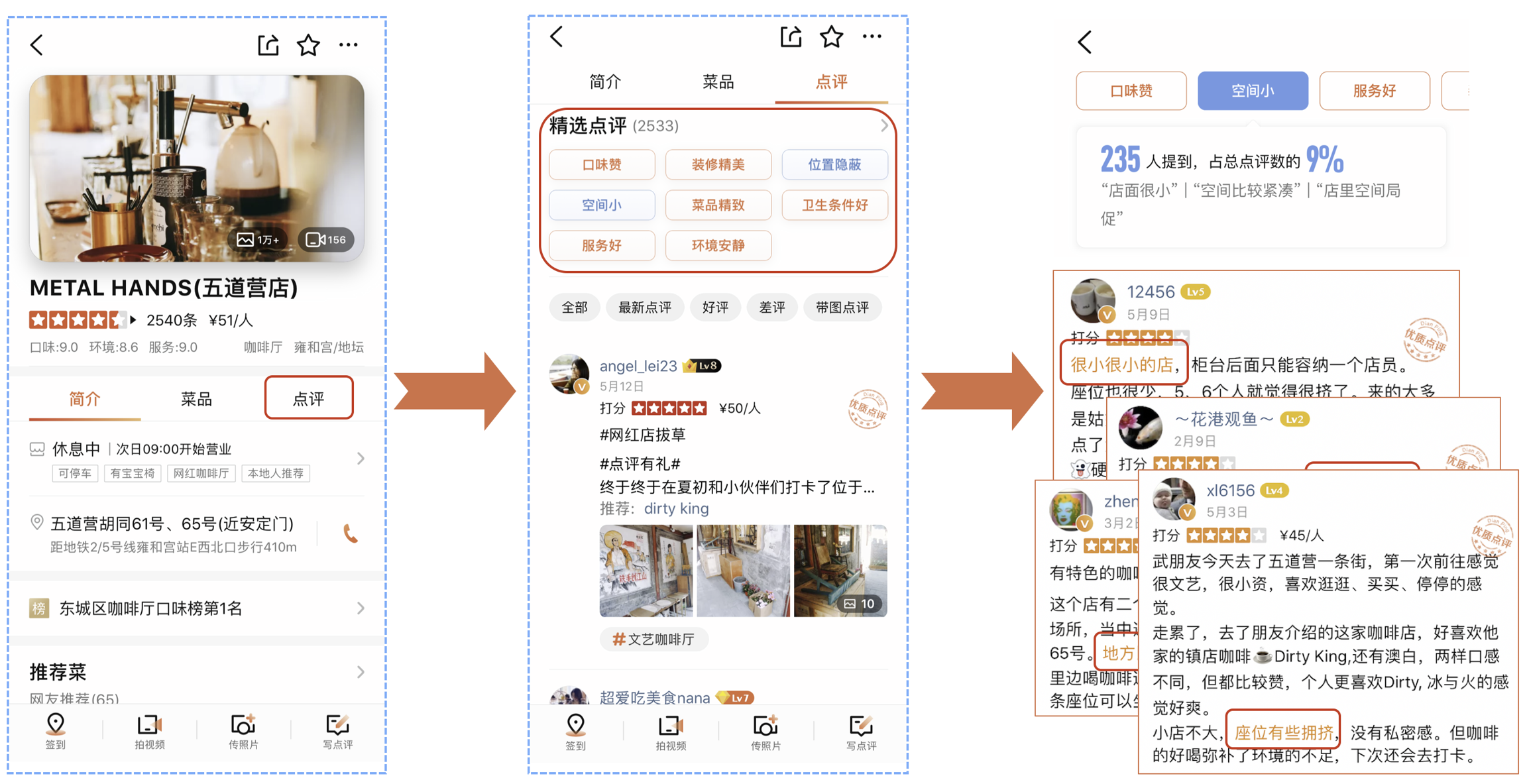
Query意图分类
在美团点评的搜索架构中,Deep Query Understanding(DQU)都是重要的前置模块之一。对于用户Query,需要首先对用户搜索意图进行识别,如美食、酒店、演出等等。我们跟内部的团队合作,尝试了直接使用MT-BERT作为Query意图分类模型。为了保证模型在线Inference时间,我们使用裁剪后的4层MT-BERT模型(MT-BERT-MINI,MBM模型)上线进行Query意图的在线意图识别,取得的业务效果如图11所示:
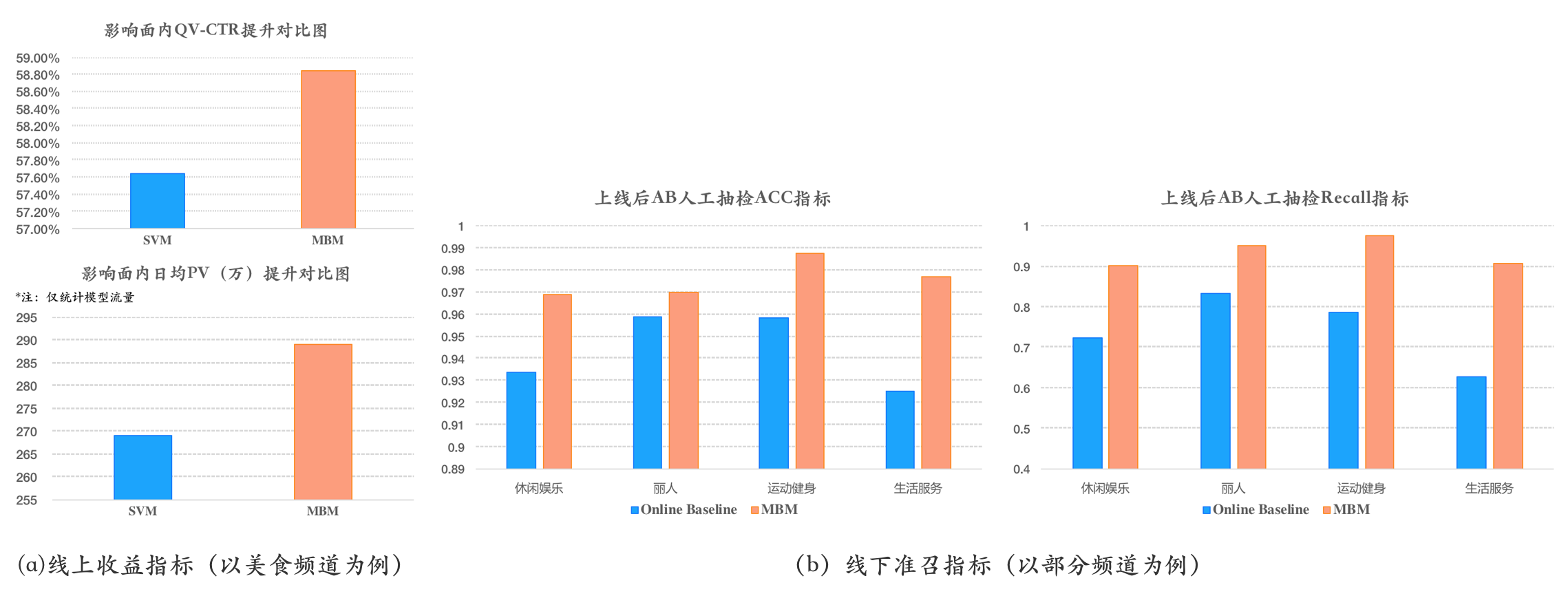
图11 MBM模型的业务效果
同时对于搜索日志中的高频Query,我们将预测结果以词典方式上传到缓存,进一步减少模型在线预测的QPS压力。MBM累计支持了美团点评搜索17个业务频道的Query意图识别模型,相比原有模型,均有显著的提升,每个频道的识别精确度都达到95%以上。MBM模型上线后,提升了搜索针对Query文本的意图识别能力,为下游的搜索的召回、排序及展示、频道流量报表、用户认知报表、Bad Case归因等系统提供了更好的支持。
推荐理由场景化分类
推荐理由是点评搜索智能中心数据挖掘团队基于大众点评UGC为每个POI生产的自然语言可解释性理由。对于搜索以及推荐列表展示出来的每一个商家,我们会用一句自然语言文本来突出商家的特色和卖点,从而让用户能够对展示结果有所感知。
对于不同的业务场景,对推荐理由会有不同的要求。在外卖搜索场景下,用户可能更为关注菜品和配送速度,不太关注餐馆的就餐环境和空间,这种情况下只保留符合外卖场景的推荐理由进行展示。同样地,在酒店搜索场景下,用户可能更为关注酒店特色相关的推荐理由(如交通是否方便,酒店是否近海近景区等)。
我们通过内部合作,为业务方提供符合不同场景需求的推荐理由服务。推荐理由场景化分类,即给定不同业务场景定义,为每个场景标注少量数据,我们可以基于MT-BERT进行单句分类微调
句间关系
句间关系任务是对两个短语或者句子之间的关系进行分类,常见句间关系任务如自然语言推理(Natural Language Inference, NLI)、语义相似度判断(Semantic Textual Similarity,STS)等。Query改写是在搜索引擎中对用户搜索Query进行同义改写,改善搜索召回结果的一种方法。Query改写可以在不改变用户意图的情况下,尽可能多的召回满足用户意图的搜索结果,提升用户的搜索体验。对改写后Query和原Query做语义一致性判断,只有语义一致的Query改写对才能上线生效。
序列标注
给定一个序列,对序列中的每个元素做一个标记,或者说给每一个元素打一个标签,如中文命名实体识别、中文分词和词性标注等任务都属于序列标注的范畴。命名实体识别(Named Entity Recognition,NER),是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等,以及时间、数量、货币、比例数值等文字。
在美团点评业务场景下,NER主要需求包括搜索Query成分分析,UGC文本中的特定实体(标签)识别/抽取,以及客服对话中的槽位识别等。NLP中心和酒店搜索算法团队合作,基于MT-BERT微调来优化酒店搜索Query成分分析任务。酒店Query成分分析任务中,需要识别出Query中城市、地标、商圈、品牌等不同成分,用于确定后续的召回策略。
在酒店搜索Query成分分析中,我们对标签采用“BME”编码格式,即对一个实体,第一个字需要预测成实体的开始B,最后一个字需要预测成实体的结束E,中间部分则为M。以图13中酒店搜索Query成分分析为例,对于Query “北京昆泰酒店”,成分分析模型需要将“北京”识别成地点,而“昆泰酒店”识别成POI。MT-BERT预测高频酒店Query成分后通过缓存提供线上服务,结合后续召回策略,显著提升了酒店搜索的订单转化率。
bert-as-service的简单使用
1.安装bert-as-service,这是一个可以利用bert模型将句子映射到固定长度向量的服务
pip install bert-serving-server
pip install bert-serving-client
注意该服务tensorflow的最低版本为1.10,tensorflow2暂不支持
下载bert预训练模型:
https://github.com/google-research/bert#pre-trained-models
2.在终端用命令启动服务
bert-serving-start -model_dir bert_chinese/
3.在Python中调用如下命令
Pytorch使用BERT
参考项目Bert-Chinese-Text-Classification-Pytorch
BERT-CNN
BERT-DPCNN
BERT-RCNN
BERT-RNN
BERT 情感分类实践
下面使用 Fine-Tuning 方法应用 BERT 预训练模型进行情感分类任务。
首先,下载一个 情感分类数据集,我们已经提前下载好并放在网盘中。
构建训练函数并开始训练。这里需要说一下,因为 GPU 内存的限制,训练集的 batch_size 设为了 4,这样的 batch_size 过小,使得梯度下降方向不准,引起震荡,难以收敛。所以,在训练时使用了梯度积累的方法,即计算 8 个小批次的梯度的平均值来更新模型,从而达到了 32 个小批次的效果。
训练结束后,可以使用验证集观察模型的训练效果。
训练结束后,还可以随意输入一些数据,直接观察模型的预测结果。
参考资料
Pytorch——BERT 预训练模型及文本分类(介绍了语言模型和词向量、BERT结构详解、BERT文本分类)
【译】BERT Fine-Tuning 指南(with PyTorch)(翻译的文章,在代码实践部分写的很详细,参考性强,2020年文章)
美团BERT的探索和实践(预训练语言模型简介、BERT介绍、美团训练加速、加入美团点评业务语料进行预训练、融入知识图谱、业务实践等,见下图)
基于BERT fine-tuning的中文标题分类实战(BERT多分类,2019年文章)

关于BERT的若干问题整理记录(BERT的基本原理是什么,BERT是怎么用Transformer的,BERT的训练过程是怎么样的,为什么BERT比ELMo效果好?ELMo和BERT的区别是什么,BERT的输入和输出分别是什么,针对句子语义相似度/多标签分类/机器翻译翻译/文本生成的任务,利用BERT结构怎么做fine-tuning,BERT应用于有空格丢失或者单词拼写错误等数据是否还是有效?有什么改进的方法,BERT的embedding向量如何的来的,BERT模型为什么要用mask?它是如何做mask的?其mask相对于CBOW有什么异同点,BERT的两个预训练任务对应的损失函数是什么,词袋模型到word2vec改进了什么?word2vec到BERT又改进了什么)
http://fancyerii.github.io/2019/03/09/bert-theory/
Last updated