Task3参考答案
Q1:HDFS是用来解决什么问题的?
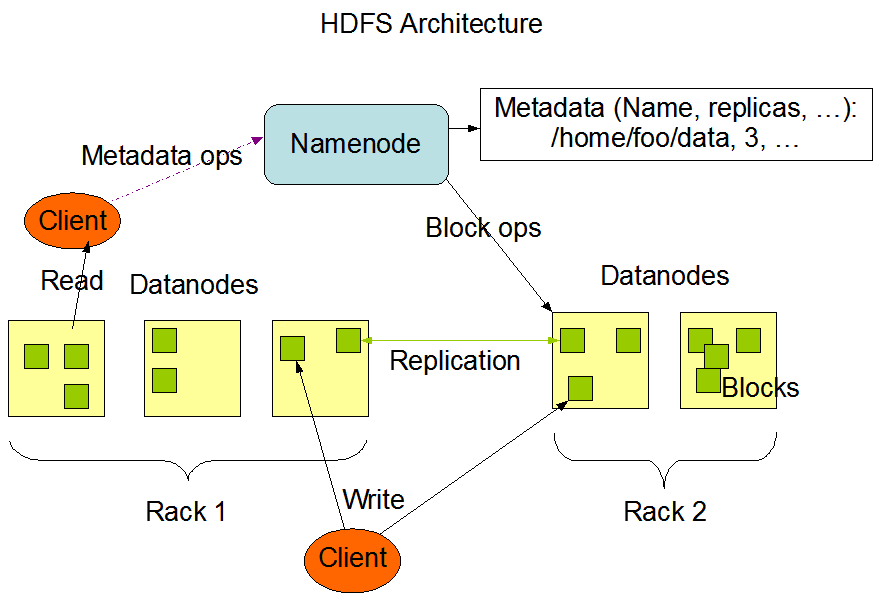{kind=link}
Q2:熟悉hdfs常用命令
# 1. 创建目录
hadoop fs -mkdir /test
# 2. 递归的创建目录,如果上级目录不存在,自动创建
hadoop fs- mkdir /user/test
# 3. 上传文件
hadoop fs -put hello.txt /user/test/
# 4. 下载文件
hadoop fs -get /user/test
# 5. 重命名或移动文件
hadoop fs -mv /user/test/hello.txt /user/test/olleh.txt
# 6. 列出当前目录
hadoop fs -ls
# 7. 递归的列出文件
hadoop fs -ls -R /
# 8. 递归删除文件,删除/user/下的所有文件
hadoop fs -rm -R /user/*
# 9. 统计hdfs对应路径下的目录个数,文件个数,文件总计大小
hadoop fs -count /user/test/
# 10. 显示hdfs对应路径下每个文件夹和文件的大小
hadoop fs -du /user/test Q3. Python操作HDFS的其他API
Q4. 观察上传后的文件,上传大于128M的文件与小于128M的文件有何区别?
Q5. 启动HDFS后,会分别启动NameNode/DataNode/SecondaryNameNode,这些进程的的作用分别是什么?
SecondaryNameNode
DataNode
Q6. NameNode是如何组织文件中的元信息的,edits log与fsImage的区别?使用hdfs oiv命令观察HDFS上的文件的metadata
Q7 HDFS文件上传与下载过程
Last updated